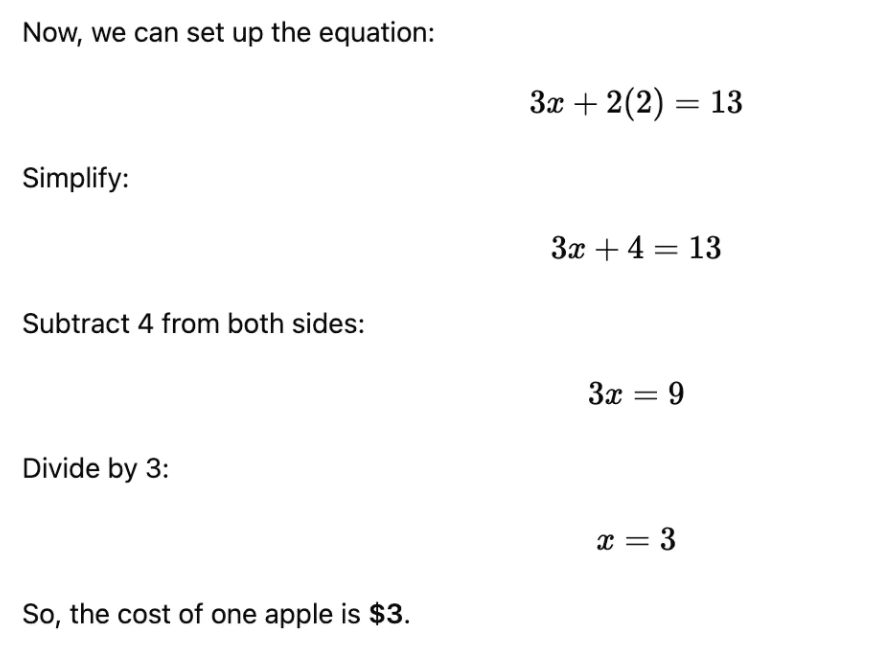May 25, 2026 LLMがこのように、ずばり答を言うのではなく過程から回答するのは、トークンに渡って推論を分散するためであって、ユーザーが読み易くするためとかではない。訓練時にそういうフォーマットで回答するように学習している。 Taiju Muto @tai2